Tensorflow Quantizaiton
During inference, precision in floats is not needed and can be reduced to using 8 bits instead of 32 bits this allows to bin continuous …
During inference, precision in floats is not needed and can be reduced to using 8 bits instead of 32 bits this allows to bin continuous …
After training we can optimize a frozen graph or even a dynamic graph by removes training-specific and debug-specific nodes, fusing common operations, and removes code …
In prediction/inference mode, variable types are unnecessary, so by freezing the graph we convert all variables in a graph and checkpoint into constants. Also there …
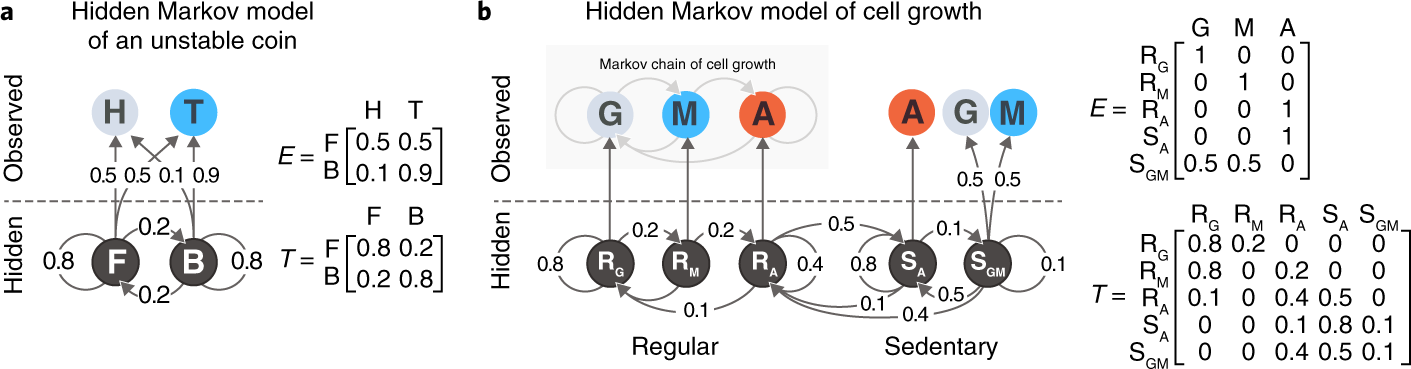
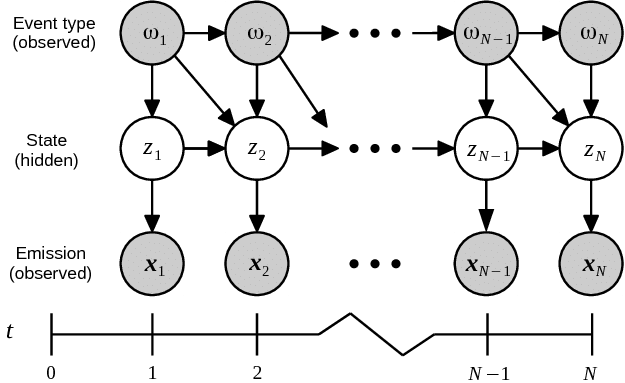
Hidden Markov Model (HMM) is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobservable (i.e. …
Hidden states are the unknowns we try to detect or predict. The Hidden states have a relationship amongst themselves called the transition probabilities. Observations are …
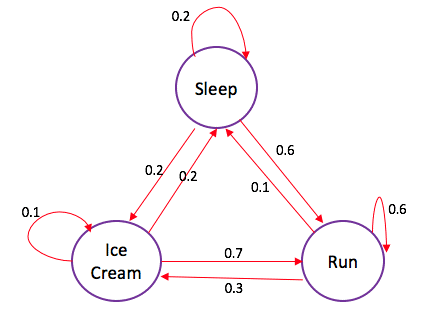
A Markov chain is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state …
To perform experience replay we store the agent’s experiences et=(st,at,rt,st+1) Then we use a random sample of these prior actions instead of the most recent …
Learns a policy which tells an agent what action to take under what circumstances. Q-learning learns a policy that is optimal in the sense that …
* Is a discrete time stochastic control process for decision making in situations where outcomes are partly random and partly under the control of a …
A variational autoencoder provides a probability distribution for describing an observation/attribute in latent/hidden space.