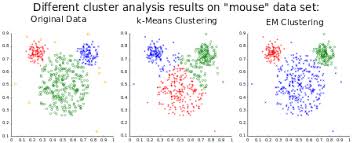
k-means clustering is a method of vector quantization which finds good inter similarity between cluster members and intra-similarity between other clusters.
k-means clustering partitions n observations into k clusters in which each observation belongs to the cluster with the nearest mean, These means are chosen so that in the next iteration the later reconstruction error is minimized.
Algorithm:
1. k initial “means” are either randomly generated or created by an initialization technique within the data.
2. k clusters are created by associating every observation with the nearest mean(every observation point has a binary of each cluster and the nearest becomes true).
3. The centroid(reference vector) of each of the k clusters becomes the new mean.
4. Steps 2 and 3 are repeated until convergence has been reached.
Complexity:
n : number of points/observations
K : number of clusters
I : number of iterations
d : number of attributes/dimensions
Time Complexity(using Euclidean proximity ):
For every iteration there are:
For step 2 – Calculating the nearest mean:
* Calculation of distances of each point to the centroid(reference vector), using a squared Euclidean proximity function we need 6 operations : two subtractions, one summation, two multiplications and one sqrt.
* Comparisons between distances
For step 3:
* Calculation of centroids(reference vectors)(cluster centre-points) (usually by average)
Which sum up to O(n * K * I * d) given that the algorithm converges in I iterations.
Space Complexity:
You only need to store the data points and centroids, hence, O((d+k)n).
 WhatsApp
WhatsApp
Comments are closed, but trackbacks and pingbacks are open.